Serverless: why microfunctions > microservices
This post follows on from a post I wrote a couple of years back called Why Service Architectures Should Focus on Workflows. In that post I attempted to describe the fragility of microservice systems that were simply translating object-oriented patterns to the new paradigm. These systems were migrating domain models and their interactions from in-memory objects to separate networked processes. They were replacing in-process function calls with cross-network rpc calls, adding latency and infrastructure complexity. The goal was scalability and flexibility but, I argued, the entity modelling approach introduced new failure modes. I suggested a solution:
Instead of carving up the domain by entity, focus on the workflows.
If I was writing that post today I would say “focus on the functions” because the future is serverless functions, not microservices. Or, more brashly:
microfunctions > microservices
The industry has moved apace in the last 3 years with a focus on solving the infrastructure challenges caused by running hundreds of intercommunicating microservices. Containers have matured and become the de-facto standard for the unit of microservice deployment with management platforms such as Kubernetes to orchestrate them and frameworks like GRPC for robust interservice communication.
The focus still tends to be on interacting entities though: when placing an order the “order service” talks to the “customer service” which reserves items by talking to the “stock service” and the “payment service” which talks to the “payment gateway” after first checking with the “fraud service”. When the order needs to be shipped the “shipping service” asks the “order service” for orders that need to be fulfilled and tells the “stock service” to remove the reservation, then to the “customer service” to locate the customer etc. All of these services are likely to be persisting state in various backend databases.
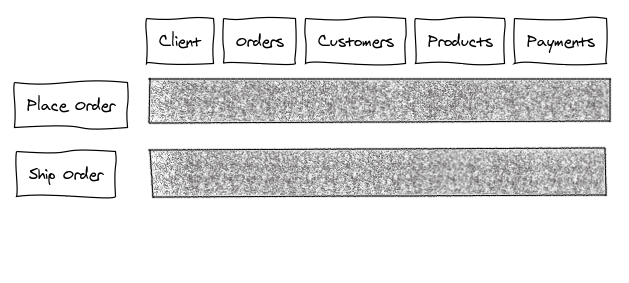
Microservices are organized as vertical slices through the domain:

The same problems still exist: if the customer service is overwhelmed by the shipping service then the order service can’t take new orders. The container manager will, of course, scale up the number of customer service instances and register them with the appropriate load balancers, discovery servers, monitoring and logging. However, it cannot easily cope with a critical failure in this service, perhaps caused by a repeated bad request that panics the service and prevents multiple dependent services from operating properly. Failures and slowdowns in response times are handled within client services through backoff strategies, circuit breakers and retries. The system as a whole increases in complexity but remains fragile.
By contrast, in a serverless architecture, the emphasis is on the functions of the system. For this reason serverless is sometimes called FaaS - Functions as a Service. Systems are decomposed into functions that encapsulate a single task in a single process. Instead of each request involving the orchestration of multiple services the request uses an instance of the appropriate function. Rather than the domain model being exploded into separate networked processes its entities are provided in code libraries compiled into the function at build time. Calls to entity methods are in-process so don’t pay the network latency or reliability taxes.
In this paradigm the “place order” function simply calls methods on customer, stock and payment objects, which may then interact with the various backend databases directly. Instead of a dozen networked RPC calls, the function relies on 2-3 database calls. Additionally, if a function is particularly hot it can be scaled directly without affecting the operation of other functions and, crucially, it can fail completely without taking down other functions. (Modulo the reliability of databases which affect both styles of architecture identically.)
Microfunctions are horizontal slices through the domain:
The advantages I wrote last time still hold up when translated to serverless terminology:
- Deploying or retiring a function becomes as simple as switching it on or off which leads to greater freedom to experiment.
- Scaling a function is limited to scaling a single type of process horizontally and the costs of doing this can be cleanly evaluated.
- The system as a whole becomes much more robust. When a function encounters problems it is limited to a single workflow such as issuing invoices. Other functions can continue to operate independently.
- Latency, bandwidth use and reliability are all improved because there are fewer network calls. The function still relies on the database and other support systems such as lock servers, but most of the data flow is controlled in-process.
- The unit of testing and deployment is a single function which reduces the complexity and cost of maintenance.
One major advantage that I missed is the potential for extreme cost savings through scale, particularly the scale attainable by running on public shared infrastructure. Since all the variability of microservice deployment configurations is abstracted away into a simple request/response interface the microfunctions can be run as isolated shared-nothing processes, billed only for the resources they use in their short lifetime. Anyone who has costed for redundant microservices simply for basic resilience will appreciate the potential here.
Although there are number of cloud providers in this space (AWS Lambda, Google Cloud Functions, Azure Functions) serverless is still an emerging paradigm with the problems that come with immaturity. Adrian Coyler recently summarized an excellent paper and presentation dealing with the challenges of building serverless systems which highlights many of these, including the lack of service level agreements and loose performance guarantees. It seems almost certain though that these will improve as the space matures and overtakes the microservice paradigm.